Olá amigos!
Hoje venho aqui falar sobre padrões de codificação de caracteres.

Para começar, o que são padrões de codificação de caracteres?
Os padrões de codificação de caracteres retratam o relacionamento entre um conjunto de caracteres com um conjunto de outra coisa, como por exemplo números ou pulsos elétricos com o objetivo de facilitar o armazenamento de texto em computadores e a sua transmissão através de redes de telecomunicação. Por exemplo o código Morse codifica as letras do alfabeto latino e os numerais como sequências de pulsos elétricos de longa e curta duração e também o ASCII que codifica os mesmos grafemas do código Morse.
Agora falando dos dois códigos mais conhecidos, o Código ASCII e o Código Unicode.
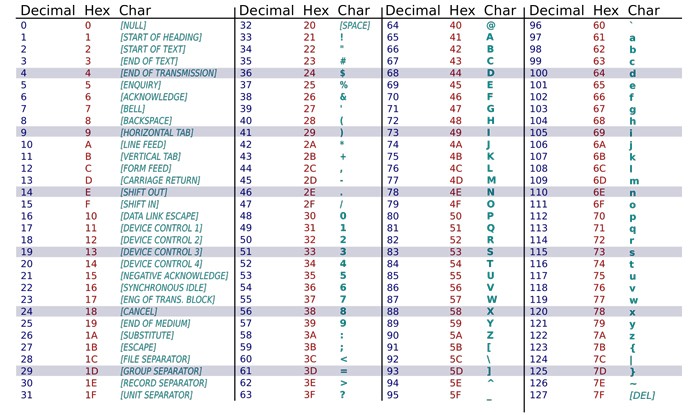
CÓDIGO ASCII

ASCII significa "American Standard Code for Information Interchange", e traduzindo para português temos "Código Padrão Americano para o Intercâmbio de Informação".
É um código binário que codifica um conjunto de 128 sinais: 95 sinais gráficos (letras do alfabeto latino, sinais de pontuação e sinais matemáticos) e 33 sinais de controle, utilizando 7 bits para representar todos os seus símbolos. Os códigos 0 a 31 não são caracteres, são chamados de caracteres de controle porque permitem fazer ações como carriage return (CR- código de fim de linha, em português) e bip sonoro (BEL). Os códigos 65 a 90 representam as maiúsculas e os códigos 97 a 122 representam as minúsculas. Basta alterar o 6° bit para passar das maiúsculas para as minúsculas, isto é, acrescentar 32 ao código ASCII em base decimal.
A codificação ASCII é usada para representar textos em computadores, equipamentos de comunicação, entre outros dispositivos que trabalham com texto. Desenvolvida a partir de 1960, grande parte das codificações de caracteres modernas a herdaram como base. O código ASCII é muito utilizado para conversão de Código Binário para Letras do alfabeto maiúsculas ou minúsculas.
CÓDIGO UNICODE
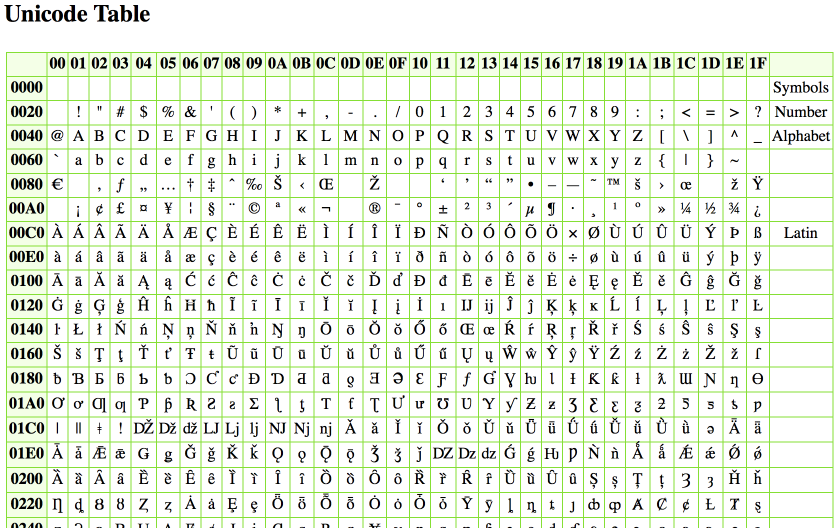
Unicode é um padrão que permite aos computadores representar e manipular, de forma consistente, texto de qualquer sistema de escrita existente. O padrão consiste em quase 138 mil caracteres, um conjunto de diagramas de códigos para referência visual, uma metodologia para codificação e um conjunto de codificações padrões de caracteres, uma enumeração de propriedades de caracteres, um conjunto de arquivos de computador com dados de referência, além de regras para normalização, decomposição, ordenação alfabética e renderização.
Em vez de usar apenas os códigos de 0 a 127, o Unicode utiliza códigos de valor bem maiores. Com isso, pode representar todos os caracteres específicos de diversos idiomas. Novos códigos são regularmente atribuídos para novos caracteres, como caracteres latinos (acentuados ou não), gregos, armênios, hebraicos, tailandeses, entre outros. Só o alfabeto chinês Kanji contém 6.879 caracteres. Assim sendo, o Unicode define uma correspondência entre símbolos e números.
Estes dois códigos (ASCII e Unicode) são os mais conhecidos pois existem mais, e já nem conseguimos "viver" sem eles.
Referências:
https://pt.wikipedia.org/wiki/ASCII
https://br.ccm.net/contents/54-o-codigo-ascii
https://i.pinimg.com/originals/42/b3/d5/42b3d5ee69c714db9dcb9c9290b345a7.png
https://pt.wikipedia.org/wiki/Unicode




{kind=link}
{kind=link}
{kind=link}
Sem comentários:
Enviar um comentário